Ошибка модели прогноза рассчитывается по формуле (7.8) [c.186]
Найдем ошибку модели прогноза s = [c.193]
Расчет ошибки модели прогноза, составленной с использованием [c.197]
Существуют по крайней мере две группы факторов, влияющих на качество прогнозов 1) связанные с подготовкой, обработкой и анализом информации 2) связанные с качеством построения модели, ее соответствием прогнозируемому процессу. Кроме того, при прогнозировании необходимо учитывать ошибки исходных данных, модели прогноза, согласования, стратегии, которые заключаются в расхождении данных прогноза и фактических данных. Ошибки исходных данных связаны главным образом с неточностью измерений, некорректностью выборки, недостоверностью показателей. Ошибки модели возникают из-за неправильного подбора целевой функции и системы ограничений, из-за низкого качества экспертизы. Ошибки согласования вызваны несопоставимостью методик расчета отдельных показателей в разных отраслях и регионах. Ошибки стратегии предопределены неправильным выбором концепции прогноза. [c.264]
Ошибка в прогнозе приводит к непоправимым результатам, к бесполезной трате в будущем ресурсов, к банкротству. Производитель (инвестор) заинтересован в прогнозе попасть в "десятку". Это обстоятельство заставляет производителей прикладывать максимум усилий для повышения качества прогнозов. Важно отметить, что для прогнозирования показателей, как своих, так и конкурентов, должны применяться одни и те же методы и модели. [c.215]
Модели прогноза изучаемых экономических показателей по аналитическому выражению тренда и по методу Брауна для линейной и квадратичной тенденции представлены в табл.1. Здесь хе приведены и ошибки прогноза в абсолютном выражении. [c.75]
По данным за второй цикл построим модель прогноза. Подберем параметр сглаживания, дающий наименьшую ошибку прогноза. Пусть а = 0,2. [c.156]
Расчет ошибки, которую дает рассмотренная модель прогноза, показан в табл. 7.17. [c.186]
| Таблица 7.17 Расчет ошибки аддитивной модели прогноза | 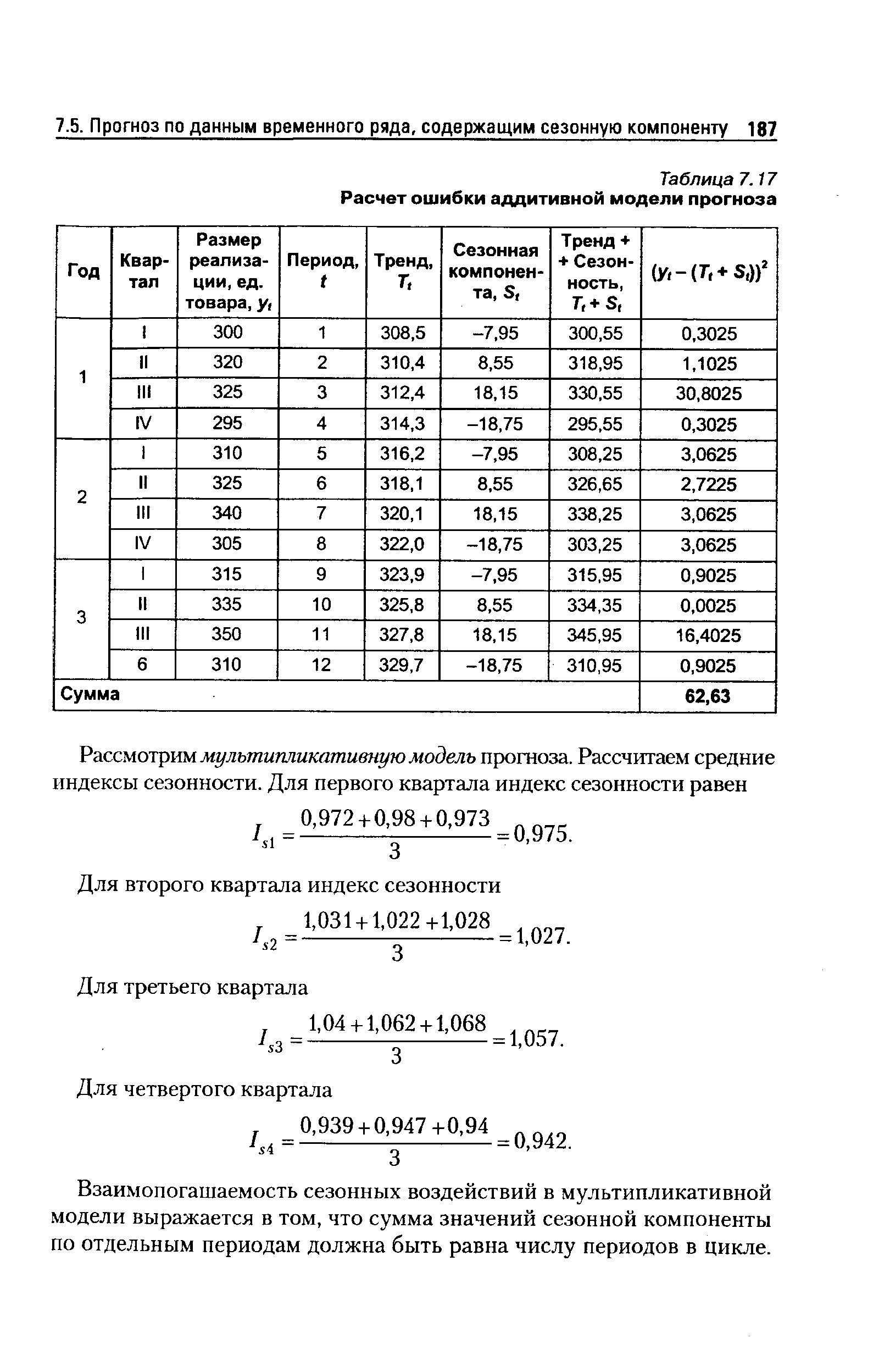 |
| Таблица 7.18 Расчет ошибки мультипликативной модели прогноза | 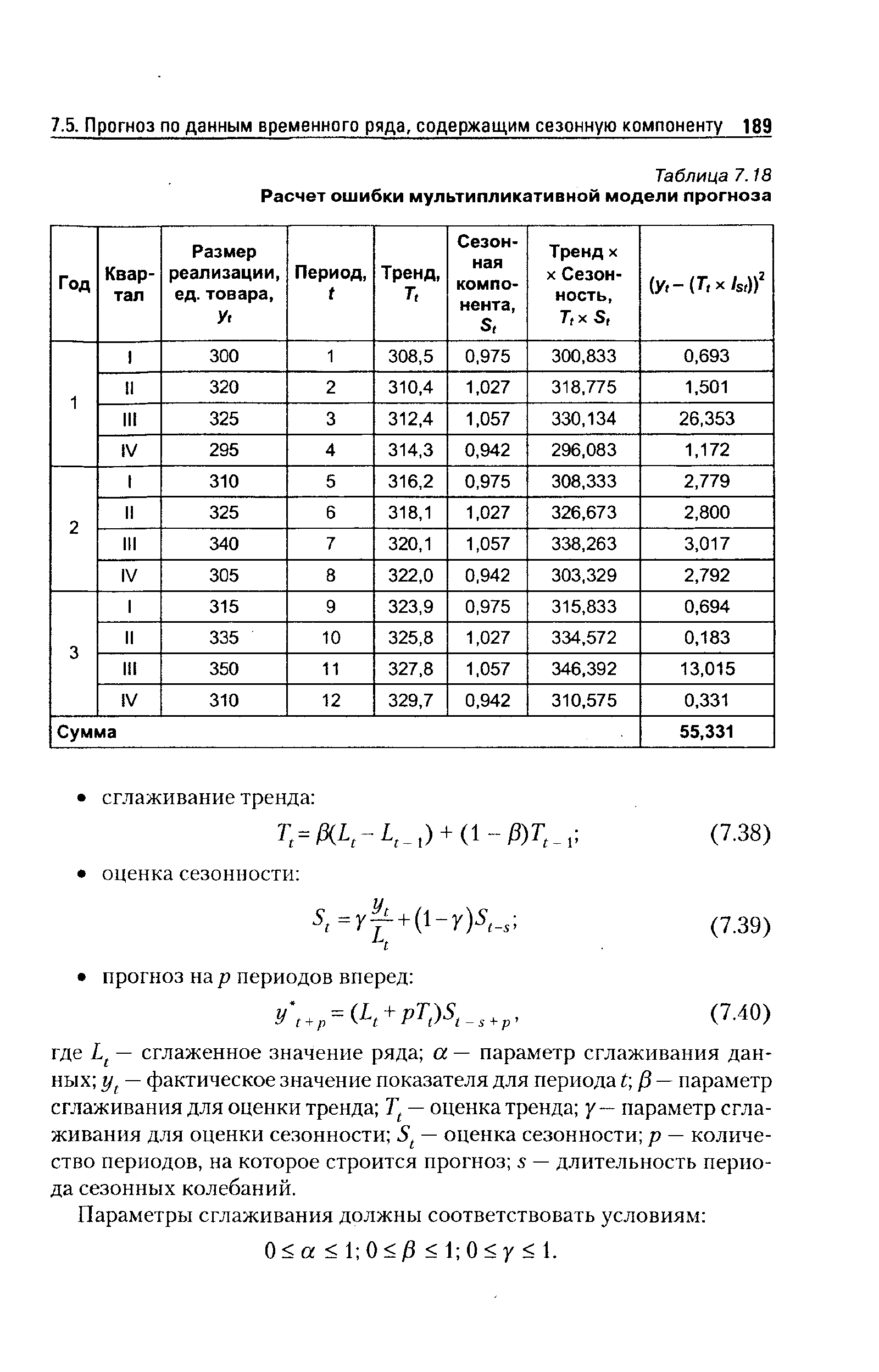 |
В Стратегии фирмы дается полный перечень соответствующих показателей. Безусловно, по перспективной модели товара, которая будет выпускаться, возможно, через 3—5 и более лет, очень трудно спрогнозировать все перечисленные в этих подразделах показатели. Поэтому из них нужно выбирать важнейшие, определяющие конкурентоспособность товара и фирмы на конкретном рынке. Ошибка в прогнозе приводит к непоправимым результатам, к бесполезной трате в будущем ресурсов, к банкротству. Производитель (инвестор) заинтересован в прогнозе попасть в десятку . Это обстоятельство заставляет производителей прикладывать максимум усилий для повышения качества прогнозов. Важно отметить, что для прогнозирования показателей как фирмы, так и конкурентов должны применяться одни и те же методы и модели. [c.93]
Ошибки в прогнозе финансовых показателей рассматриваемого периода скажутся на размере рублевой прибыли предприятия, эквивалент же ее в валюте мало подвержен колебаниям. Однако менеджеров ООО Профи , в первую очередь, интересует именно валютный эквивалент прибыли, поскольку кредит на осуществление инвестиций будет получен в валюте. Учитывая это обстоятельство, анализ модели при различных возможных темпах инфляции нецелесообразен. Девальвация рубля может затормозить работу предприятия на 1—2 месяца, но в долгосрочном периоде повысит конкурентоспособность продукции по сравнению с импортом, что будет способствовать расширению сбыта продукции. [c.330]
Если вы хотите делать прогнозы с помощью полученной вами модели, то стоит посмотреть на стандартную ошибку модели. Менеджер не оценит вашу работу, если вы получите высокое значение коэффициента корреляции но диапазон ошибки прогнозирования составит 50% от предсказываемого значения. Существует процедура строгой проверки полученных результатов, предусматривающая использование контрольной выборки. [c.819]
Как можно видеть из (3), оцениваемая ошибка модели с, /Г МП г НО. также будет иметь стандартное нормальное распределение. Однако дисперсия этой ошибки будет зависеть от макроэкономических показателей, что сделает оценки /3 менее эффективными. Для снижения этой зависимости можно разделить все уравнение на некоторый макроэкономический показатель, предположительно хорошо коррелирующий с вектором МГЙ. В качестве такого показателя часто используют численность населения. Однако можно использовать и интегральный показатель деловой активности территории - ВРП. Рекомендуется попробовать несколько показателей для определения тех, что дают оценки из модели с наименьшей ошибкой прогноза. Допустим, это чис- [c.71]
Если зависимость мультипликативная, то ошибки рассчитываются аналогичным образом. Например, если предположить возможность ошибки в прогнозе доли налоговых отчислений, то формула для ошибки модели переписывается так [c.83]
Простейшим из интуитивных правил, получившим название правила статических ожиданий, является предпосылка о том, что следующий год будет идентичен текущему. Индивидуумы могут также подвергать пересмотру свои ожидания относительно будущего в соответствии с прошлыми ошибками в прогнозах этот подход получил название правила адаптивных ожиданий. Более тонкий механизм, известный под названием рациональные ожидания, предполагает, что в процессе формирования своих ожиданий агенты эффективно используют всю находящуюся в их распоряжении информацию, а также собственное понимание существующей экономической модели управления. Эмпирические же свидетельства относительно того, как люди на практике формируют свои ожидания, не позволяют сделать окончательных выводов. [c.64]
Роль прошлых затрат заключается в том, что на их основе можно построить прогноз поведения затрат в будущем. Но в ситуационных моделях участвуют только проектные затраты. Обычно в анализе затрат используют общие, а не удельные суммы. Если постоянным расходам придается модель поведения переменных, это может привести к ошибкам. [c.222]
Вычленение и анализ такого элемента временных рядов, как случайные колебания, может использоваться для определения вероятных ошибок и оценки надежности модели прогнозирования. Случайные колебания расцениваются как ошибки прогноза. Разность между фактическими и прогнозируемыми значениями характеризует допущенную ошибку. Для оценки ошибок существуют статистические показатели — средняя ошибка и среднеквадратическая ошибка. Чем меньше значения этих критериев, тем больше надежность прогнозной модели. [c.82]
Это значение в определенной степени указывает на точность примененной модели прогнозирования. Малое значение среднеквадратического указывает на большую надежность прогнозной модели. Среднеквадратическое можно использовать для оценки доверительных пределов любого прогноза. Это значение можно применять как оценочный показатель среднеквадратического отклонения, и при условии того, что ошибки образуют нормальное распределение, 95%-ные доверительные пределы для фактического значения, основанного на прогнозе F, определяются следующим образом [c.213]
Таким образом, при этом прогнозе фактический показатель объема производства может быть от 77 до 103 тонн, что указывает на то, что прогнозная модель не выдает очень надежного результата. Во многих ситуациях вероятная ошибка в 12.5 тонны при прогнозе в 90 тонн (или 14%-ная ошибка) может быть неприемлемой. [c.214]
Эффективность модели, используемой при прогнозировании, можно измерить с помощью приемов, описанных в предыдущем разделе. Главным образом, нас интересует точность прогнозных значений. Ошибка прогноза — это разница между прогнозным и фактическим значениями. Независимо от примененной модели важно оценить ее эффективность с точки зрения точности, и в идеале ошибки прогноза должны быть сведены к минимуму. Эффективность конкретной модели зависит от ряда факторов, о которых мы и расскажем далее. [c.214]
Вторая причина, по которой линейная регрессионная модель оказывается предпочтительнее других, — это меньший риск значительной ошибки прогноза. [c.18]
Пусть yn+i — прогнозное значение, которое получается из модели для еще не наблюдаемых значений регрессоров. Величина M(yn+l — yn+i)2 может рассматриваться как средняя ошибка прогноза. Следует выбрать ту модель, для которой эта ошибка меньше. [c.244]
Таким образом, в условиях значительной неопределенности исходной информации (о величине запасов и параметрах пластов), отсутствия достаточных данных о возможном составе и пространственном размещении запасов, а также при ошибках, связанных с прогнозом затрат на подготовку запасов, можно в процессе оптимизации развития и размещения нефтедобычи использовать экспертные оценки. Иной подход связан с включением в модели характеристик типа плотности вероятности открытия запасов определенных размеров. [c.126]
Ошибка прогноза исходных показателей, используемых в экономико-математических моделях перспективного отраслевого планирования, возрастает с удлинением периода планирования и тем более с ростом детализации модели. Например, потребность в отдельных нефтепродуктах может быть наиболее точно определена на ближайшие годы. Причем для первых лет плакирования разукрупнение до определенного момента исходной информации может привести к увеличению ее точности вследствие уменьшения ошибки агрегирования. С переходом -к 10— [c.24]
Построение динамической модели с неоднородной структурой основывается на следующих предпосылках ошибка прогноза основных исходных показателей, определяющих развитие отраслевого комплекса, уменьшается при их последовательном агрегировании практические расчеты на ближайший плановый период должны основываться на достаточно детальной номенклатуре продуктов и ресурсов. Решения, касающиеся последующих этапов, могут быть своевременно скорректированы в процессе скользящего планирования. [c.25]
Когда говорят об "искусственном интеллекте", имеют в виду так называемые эвристические программы, которые способны решать задачи - примерно так же, как это делает человек. Работу компьютера, решающего эвристическую задачу, в принципе можно назвать "разумной" он оценивает условия, принимает решения и даже учится на своих ошибках. Функция автоматического распознавания моделей позволяет машине учиться принимать решения и делать прогнозы на основе классификаций различных объектов или индикаторов. В данном случае значение слова "модель" отлично оттого, которое использовалось при описании "графических моделей". Цель автоматического распознавания моделей -получение синергетического эффекта путем одновременной оценки данных всех индикаторов (вместо того, чтобы рассматривать каждый из них по отдельности). [c.424]
Где каждое B(ijt) представляет собой фактор, выраженный в терминах корреляционного коэффициента (t, t) и, обычно, называется коэффициентом (i,t) инверсной корреляционной матрицы. Формула (1) выражает тот факт, что каждое прошлое изменение г,- влияет на будущее изменение г, пропорционально величине этого изменения и коэффициенту B(i,t)/B(t,t), который не равен нулю только, если существует ненулевая корреляция между моментами времени int. С помощью формулы (1) мы получаем наилучший линейный прогноз, в том смысле, что мы можем минимизировать ошибку в предсказании (минимизация вариации). Принимая на вооружение эту линейную модель, можно получить мощную торговую стратегию покупать, если mt > 0 (ожидаемый рост будущих цен) и продавая, если /я, < О (ожидаемое падение будущих цен). [c.50]
Ошибки исходных данных связаны главным образом с неточностью экономических измерений, некачественностью выборки, искажением данных при их агрегировании и т.д. Ошибки модели прогноза возникают вследствие упрощения и несовершенства теоретических построений, экспертных оценок и т.д. Правильность модели прогноза (в т.ч. оценки ее параметров) проверяется ретроспективным расчетом, который можно сопоставить с действительным ходом исследуемого процесса. Однако и это не дает полной гарантии качества прогноза на будущее, так как условия могут измениться. Ошибки согласования часто происходят из-за того, что статистические данные в народном хозяйстве подготавливаются разными организациями, которые применяют различную методологию расчетов. Ошибки стратегии — результат, главным образом, неудачного выбора оптимистического или пессимистического вариантов прогноза. (См. Диапазон осуществимости прогноза.) [c.256]
Пятый этап — вычисление ошибки модели прогноза. Из фактического значения вычитаются сезонная компонента и тренд (аддитивная модель), для полученных остатков определяется среднее квадратиче-ское отклонение. В мультипликативной модели из фактического значения вычитается произведение индекса сезонности и тренда. По полученным остаткам также рассчитывается ошибка прогноза. Следует напомнить, что чем больше период упреждения прогноза, тем его точность будет меньше. [c.183]
С помощью процедуры Поиска решения MS Ex el можно найти параметры сглаживания более точно, что может обеспечить меньшую ошибку модели прогноза. [c.193]
Несколько неожиданным оказалось то, что ошибка прогнозов в местной валюте (т.е. без учета эффектов обмена валют) мало отличалась от ошибки долларовых прогнозов. В отдельных случаях, в частности, для Канады и Австралии, ошибка для местной валюты была выше, чем для долларового прогноза. В применении к интернациональному портфелю обменным риском можно управлять, приняв предположение о равенстве покупательных способностей и применяя к совокупному портфелю модель САРМ с одним бета (см. [4]), или же, не предполагая равенства покупательных способностей, используя для каждой валюты свой показатель риска. Модели с несколькими факторами риска были предложены Россом и Уолшем [232]. [c.162]
ОШИБКИ В ПРОГНОЗИРОВАНИИ [fore asting bias] — расхождения между данными прогноза и действительными (фактическими) данными. Закономерности О.в.п. изучаются математико-статисти-ческими методами. Различаются четыре вида ошибок исходных данных, модели прогноза, согласования, стратегии. [c.256]
Тип 2 прогноз (восстановление) неизвестных значений интересующих нас индивидуальных (Y (X) = (т] = X)) или средних (Уср (X) = Е (г = X) значений исследуемых результирующих показателей по заданным значениям X соответствующих (предикторных) переменных. При такой постановке задачи статистический вывод включает в себя описание интервала (области) Ар (X) вероятных значений прогнозируемого показателя Уср (X) или Y (X) и сопровождается величиной доверительной вероятности Р, с которой гарантируется справедливость нашего прогноза, формализуемого с помощью утверждения вида (Y (X) g Ар (X) или Уср (X) Лр (X) . Как и в предыдущем случае, выбор формы связи (т. е. класса допустимых решений F и конкретного вида функции f (X) в модели (В.З)) и состава предикторов X играет подчиненную роль и нацелен исключительно на минимизацию ошибки получаемого прогноза. Однако в данном случае (в отличие от предыдущего) исследователь существенно использует значения функции f (X), которые являются отправной точкой при построении прогнозных интервалов (областей) АР(Х). Последние обычно определяются в форме множества всех тех значений Y, которые удовлетворяют неравенствам [c.20]
Проверим, как адаптируется выбранная модель прогноза к появлению новых данных. Фактическое значение спроса за 21-й дн. 5 ед. не совпало со средним прогнозируемым значением, но находится в доверительном интервале прогноза. С помощью процедуры Поиска решения MS Ex el определим новое значение параметра сглаживания с учетом новых данных. Параметр сглаживания стал равен 0,31, прогноз на 22-й день — 7 ед., ошибка прогноза — 2,07, нижняя граница прогноза — 7 - 2,07 х 1,86 = 3 ед., верхняя граница — 11 ед. [c.157]
Пусть стоимость снижения ошибки прогноза мак-ропоказателяу на 1% -МСМП, а снижения ошибки модели по налогу/ 1% - МСМОдШщ. Так как один и тот же макропоказатель может использоваться в прогнозах разных налогов, то суммарное снижение общей ошибки в процентах в результате уточнения данного макропоказателя на 1% будет равно [c.83]
Найденное уравнение регрессии значимо на 5%-ном уровне по /-критерию, так как фактически наблюдаемое значение статистики F= 24,32 > /o,05 i i9 = 4,35. Можно показать (например, с помощью критерия Дарбина—Уотсона) (см. далее, 7.7)), что возмущения (ошибки) е/ в данной модели удовлетворяют условиям классической модели и для проведения прогноза могут быть использованы уже изученные нами методы. [c.148]
На Рис. 155 сравнивается реальная и прогнозируемая эволюция индекса на 1999 год и далее [216]. Индекс Nikkei не только испытал разворот тренда, но и количественные изменения совпадают с данными предсказания с впечатляющей точностью. В частности, прогноз роста индекса на 50% подтвердился полностью. Также абсолютно точно был предсказан еще один разворот тренда, появившийся в начале 2000 года, что также совпадает с прогнозируемым временем разворота. Предсказанный и фактически достигнутый максимум очень близки. Важно отметить, что ошибка между кривой и реальными данными не увеличилась после того, как последние данные за 1999 год были использованы в подгонке. Это говорит о том, что предсказание хорошо выполнялось более, чем в течение года. Более того, поскольку относительная ошибка между соответствием и действительностью находилась в пределах 2% в течение 10-ти лет, не только предсказание было успешным, но и модель, лежащая в его основе. [c.331]