В анализе поведения затрат наиболее трудной задачей является сбор большого количества данных. Проблемы возникают при выборе переменных, из-за отсутствия данных, инфляции, нехарактерных данных. [c.245]
Определение параметров матриц анализа портфеля продукции проводится для того, чтобы иметь ясность в отношении сбора необходимой информации, а также для выбора переменных, по которым будет проводиться анализ портфеля. Например, при изучении привлекательности отрасли в качестве таких переменных могут служить размер рынка, степень защищенности от инфляции, прибыльность, темп роста рынка, степень распространенности рынка в мире. [c.228]
| Рис. 10.8. Модель выбора переменных для исследования влияния культуры на организацию |  |
ВЫБОР ПЕРЕМЕННЫХ СЕГМЕНТИРОВАНИЯ [c.34]
Неупорядоченный выбор переменных сегментирования. Выбор переменных сегментирования осуществляется произвольно. Главное — это полезность полученных сегментов с точки зрения управления ими. [c.34]
В этой части процесса сегментирования не существует заведомо правильных или неправильных ответов. Отсюда требование к менеджерам нужно построить выбор переменных под конкретные нюансы своего рынка. Например, могут существовать покупатели, для которых характерна осведомленность или повышенная реакция на внешние тенденции. К ним можно отнести людей, обеспокоенных экологическим ущербом утилизации продуктов и процессов производства. Другой вариант выяснить, изменение дохода каких покупателей наиболее точно соответствует общей экономической ситуации. Или, наоборот, могут быть покупатели, чей бизнес, рынок или стиль жизни очевидным образом зависит от политических сил и государственного регулирования. [c.136]
По этой причине по возможности следует отбирать факторы, которые отражают изменения в ожидании, а не в реализации, поскольку последние обычно включают оба типа изменений. Одним из способов достижения этой цели является выбор переменных, которые включают изменения в рыночных ценах. Так, разность в доходности двух портфелей — одного, состоящего из акций, которые предположительно не зависят от инфляции, и другого, состоящего из акций, которые предположительно зависят от инфляции, — может быть использована в качестве фактора, измеряющего изменения инфляционных ожиданий. При построении факторных моделей с помощью временных рядов часто опираются именно на такого рода рыночные суррогаты изменений в прогнозах относительно фундаментальных макроэкономических показателей. [c.303]
| Рис. 4.18. Выбор переменных для анализа |  |
Как уже говорилось, наш выбор переменных обусловлен приобретенным ранее опытом и образованием. В результате этого, мы непреднамеренно исключаем из рассмотрения некоторые виды управляемых переменных и сосредоточиваем свое внимание только на некоторых традиционно используемых переменных. [c.72]
Большинство из нас подходит к решению задачи со своими представлениями о существенных и- несущественных факторах, что и определяет выбор переменных. Это представление обусловлено нашим образованием или, если говорить более конкретно, областью наших научных либо профессиональных интересов. Каждая такая концептуальная установка исключает рассмотрение уместных управляемых переменных, которые не исключаются при другой концептуальной установке . Поэтому предлагается привлекать к формулировке проблем междисциплинарные и межпрофессиональные группы. [c.82]
Информационную подсистему можно автоматизировать в значительной мере за счет использования ЭВМ. Процедуры выбора переменных, выступающих в качестве симптомов, и их анализа также можно автоматизировать на основе применения методов статистического контроля качества. Процессы запоминания и сравнения данных также могут быть автоматизированы полностью, процесс принятия решений — частично и процесс диагностирования — лишь в незначительной степени. [c.211]
Выбор переменных. Различают переменные состояния, скорости (роста) факторов и др. Они в свою очередь подразделяются на вспомогательные и управляющие. [c.16]
| Таблица 1.14 Выбор переменных для оценки жизненного цикла | 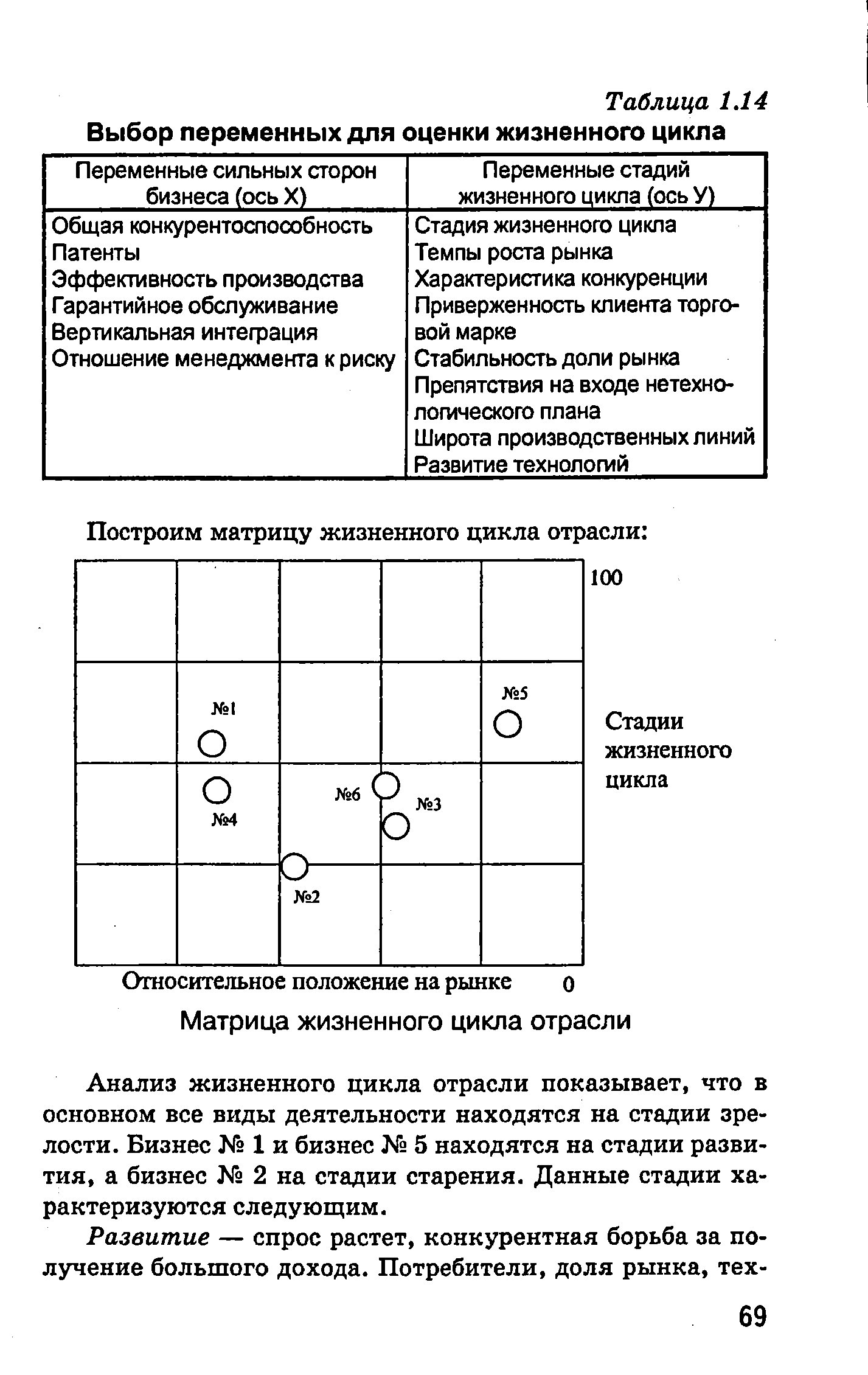 |
Помните, что выбор переменных сегментирования — это процесс с изрядной долей субъективизма, поэтому редко когда можно категорично заявить, что существует какой-то один наилучший способ сегментирования конкретного рынка. Главное, чтобы с помощью выбранных переменных действительно можно было разумно и понятно выделить отдельные потребности покупателей. К примеру, покупателей автомобилей теоретически можно было бы различать по цвету волос, однако вряд ли от этого зависят их потребности в данной товарной категории Такой подход будет лишен всякого смысла. [c.117]
В качестве критических замечаний можно сказать следующее выбор переменных для анализа очень условен, не существует критерия, по которому можно было бы определить, какое число переменных требуется для анализа трудно оценить, какие из переменных наиболее значимы присвоение удельных весов переменным при конструировании шкал матрицы очень затруднено трудно сравнивать бизнес-области, относящиеся к разным отраслям, так как переменные сильно привязаны к отрасли. [c.197]
Выбор переменных и их ранжирование могут быть сделаны в зависимости от конкретной обстановки. Если нас интересуют поставки товара с оплатой только в свободной валюте, все остальные страны исключаются. Также не представляют интереса регионы, из которых затруднен перевод валютной выручки. [c.56]
Главный вопрос здесь - выбор переменных решения. Запишите все возможные способы распила 20-футовых бревен на стандартные куски и соответствующие этим способам величины обрезков. [c.52]
Шаг 4.1. Выбор переменной, вводимой в список базисных переменных. [c.344]
Шаг 4.2. Выбор переменной, выводимой из списка базисных переменных. [c.344]
Под идентификацией модели понимается выбор переменных модели, а также вида и параметров ее уравнений с последующей их оценкой на основе статистических данных, полученных в результате наблюдения или эксперимента (см. Оценка параметров модели). [c.113]
Выбор переменных и детализация отдельных параметров осуществляются в зависимости от специфики конкретного предприятия. [c.159]
Выбор переменных, описывающих изучаемые характеристики, построение нового графа непосредственных связей и его анализ. [c.46]
Целевая функция оценивает качество плана в зависимости от выбора переменных х , ху. .., хп. Лучшее значение функции (обычно максимальное или минимальное) так же, как и соответствующий план, называется оптимальным. [c.303]
Ранее мы упоминали, что существует два широких подхода к сегментации, один из которых — априорная сегментация. Обратите внимание, что сегментация выгоды — пример второго подхода, называемого эмпирической сегментацией. В то время как априорная сегментация начинается с выбора переменной, типа переменной дохода или частоты потребления, а потом проверяет, отличаются ли люди на различных уровнях этих переменных в выгодах, которые они ищут, или торговых марках, которые они покупают в товарной категории эмпирическая сегментация работает наоборот. Например, в сегментации выгоды, мы начинаем с опроса людей о том, какие выгоды они ищут в товарной категории. Потом мы группируем их в сегменты, основанные на подобии выгод, которые они ищут (часто используя разнообразную статистическую технику, называемую кластерным анализом), затем находим то, что делает эти сегменты (созданные только на основе рейтинга важности выгод) различными, с точки зрения демографии, и т.д. Очень важно в формировании рыночных сегментов посредством такого кластерного анализа удостовериться с помощью соответствующих статистических испытаний, что появляющиеся в результате сегменты надежные и устойчивые [17]. [c.188]
ЭФФЕКТИВНОСТЬ УДОВЛЕТВОРЕННОСТЬ Рис. 13.8. Модель выбора переменных для исследования влияния культуры [c.552]
Для множественной регрессии данный тест обычно проводится для той объясняющей переменной, которая в наибольшей степени связана с QI. При этом k должно быть больше, чем (т + 1). Если нет уверенности относительно выбора переменной Xj, то данный тест может осуществляться для каждой из объясняющих переменных. [c.218]
Поэтому мы анализируем отдельную фирму и ее решения в конкретных обстоятельствах. Мы рассматриваем в качестве нормы дисконтирования норму ге в условиях, когда налогообложение существует, но для определения чистого потока денежных средств до налогообложения выбираем положение фирмы до того, как налог выплачен. Это означает, что мы допускаем, что на отдельно взятой фирме налог на прибыль не влияет на Ге. Очевидно, что это не так в случае гь, что и определяет наш выбор переменных для анализа. [c.365]
Целевая функция может максимизироваться, например, если с% означает прибыль, стоимость и т.д., или минимизироваться, если эти оценки измеряют затраты, себестоимость и т.д. Форма модели также будет зависеть от выбора переменных Xik. Вне зависимости от этих полученных модификаций модели она имеет некоторое сходство с транспортной. Однако наличие в одной из групп ограничений множителей А приводит к известным осложнениям при анализе этих моделей. [c.29]
Возможно, самая важная часть формулирования проблемы кластеризации — это выбор переменных, на основе которых проводят кластеризацию. Включение даже одной или двух посторонних (не имеющих отношение к группированию) переменных может исказить результаты кластеризации. Задача состоит в том, чтобы выбранный набор переменных смог описать сходство между объектами с точки зрения признаков, имеющих отношение к данной проблеме маркетингового исследования, следует выбирать, исходя из опыта прошлых исследований, теории или тестируемой Экспериментатор должен обладать интуицией и уметь делать выводы. [c.751]
| Рисунок 3.16. Выбор переменных для нелинейного анализа |  |
Джон Такер провел тщательное сравнительное исследование использования логистической регрессии и нейронных сетей и определил следующее их принципиальное различие. которое сохраняет свое значение и при общем сопоставления статистики и нейрокомпьютинга. В то время как статистические методы фокусируются на оптимальном методе выбора переменных, нейрокомпьютинг ставит во главу угла предобработку этих переменных. Если нейронная сеть представляет собой многослойный персептрон, то функцией скрытых слоев и является такая последовательная предобработка данных. Вследствие этого нейронные сети занимают уникальное место среди методов обработки данных, превосходя их в универсальности и сложности, оставаясь при этом data-driven методом мало чувствительным к форме данных как таковых. [c.205]
Выбор переменных, которыми мы стремимся управлять, и способ, с помощью которого мы пытаемся это делать, определяется тем, что, по нашему мнению, составляет природу взаимосвязей, существующих между переменными, а также между переменными и конечным результатом той или иной линии поведения. Наиболее важным видом взаимосвязей, рассматриваемых при решении проблем, являтся причинная зависимость, Такая зависимость может быть строгой (выбранная линия поведения полностью предопределяет исход) или нестрогой — слабой, когда выбранная линия поведения не обязательно влияет, или воздействует, на исход. Слабую (вероятностную, или недетерминированную) причину иногда называют генератором (produ er), а ее следствие — продуктом. Генератор (например, жел,удь) с некоторой вероятностью способен произвести соответствующий продукт (дуб), однако это событие не является достоверным. Слабая причинная зависимость наблюдается, как правило, в реальных условиях, а строгая причинная зависимость— в лабораторных или близких к ним. [c.107]
Иногда, вместо вычисления значений факторов, исследователь может выбрать переменные-заменители. Выбор переменных-заменителей (surrogate variables), заключается в выделении нескольких из исходных переменных для использования их в последующем анализе, [c.730]