Суть работы нейросетевых пакетов заключается в том, что на вход подаются данные с уже известными ответами, которые используются для обучения нейросети. После окончания обучения сеть готова делать предсказания, используя аналогичные входные данные. Для получения более точных результатов, анализа влияния различных параметров и данных, проверки работы индикаторов, самоконтроля в различных ситуациях сеть проверяют на имеющейся базе данных. [c.138]
Используя в качестве образца значение ставки следующего дня — IRt+i — обучим сеть. Во время процесса обучения сеть обобщает влияние каждого входного параметра на ставку завтрашнего дня — IRt+i. [c.141]
| Рисунок 5. Обучение сети как задача оптимизации |  |
Обучение сетей обычно начинается с малых случайных значений весов. Пока значения весов малы по сравнением с характерным масштабом нелинейной функции активации (обычно принимаемом равным единице), вся сеть представляет из себя суперпозицию линейных [c.66]
Количество нейронов в соревновательном слое определяет максимальное разнообразие выходов и выбирается в соответствии с требуемой степенью детализации входной информации. Обученная сеть может затем классифицировать входы нейрон-победитель определяет к какому классу относится данный входной вектор. [c.80]
Как мы видели, алгоритм обучения сетей, понижающих размерность, сводится к обычному обучению с учителем, сложность которого была оценена ранее. Такое обучение требует [c.82]
Можно пойти еще дальше и вместо среднего использовать взвешенное мнение сетей-экспертов. Веса выбираются адаптивно максимизируя предсказательную способность комитета на обучающей выборке В итоге, хуже обученные сети из комитета вносят меньший вклад и не портят предсказания. [c.162]
Полное число связей в обученной сети составляет (N + N0)Nh. Можно показать, что связь между входным и промежуточным нейроном w,. можно удалить без снижения точности [c.171]
Полезность обучения сети на примерах обанкротившихся фирм состоит также в том, что такая сеть вырабатывает дискриминантную функцию - численный показатель финансового здоровья [c.188]
В данной главе были рассмотрены различные подходы к анализу рисков. Одни из них в для формирования обучающей выборки используют мнения авторитетных рейтинговых агентств, другие - опираются на объективные данные о банкротствах. Наконец, альтернативный подход использует для обучения сети "непомеченные" финансовые данные, предлагая методику сравнительного финансового анализа. [c.197]
Другой способ избавиться от переобучения заключается в том, чтобы измерить ошибку сети на некотором множестве примеров из базы данных, не включенных в обучающее множество, — подтверждающем множестве. Ухудшение характеристик сети при работе с этим множеством указывает на возможное переобучение. Наоборот, если характеристики улучшаются, это значит, что обучение продолжается. Таким образом, переобучение можно обнаружить, наблюдая за тем, насколько последовательно уменьшается ошибка во время обучения сети. В любом реальном (не смоделированном на компьютере) приложении нужно использовать подтверждающее множество, так как уровень шума заранее не известен. [c.34]
Взяв 4-мерный вход и не предполагая никаких знаний о модели, мы умышленно имели дело с сетью, содержащей лишние элементы. Как это обстоятельство повлияло на формирование весов в результате обучения сети Для лучшего понимания вопроса в табл. 3.5 веса обученной сети представлены в сравнении с аналогичными весами двумерной сети (последние указаны в скобках). Веса входов, соответствующих f — 1 и t — 2, имеют для 4-лаговой и 2-лаговой моделей один и тот же знак и примерно одинаковую величину (по отношению к порогу). Этот факт, а также малая среднеквадратичная ошибка прогноза 4-2-1 сети на новых образцах говорят об устойчивости характеристик сети при добавлении в нее лишних элементов. [c.93]
| Таблица 6.3. Квадратный корень из средней квадратичной ошибки на подтверждающем множестве для полностью обученных сетей различной архитектуры | 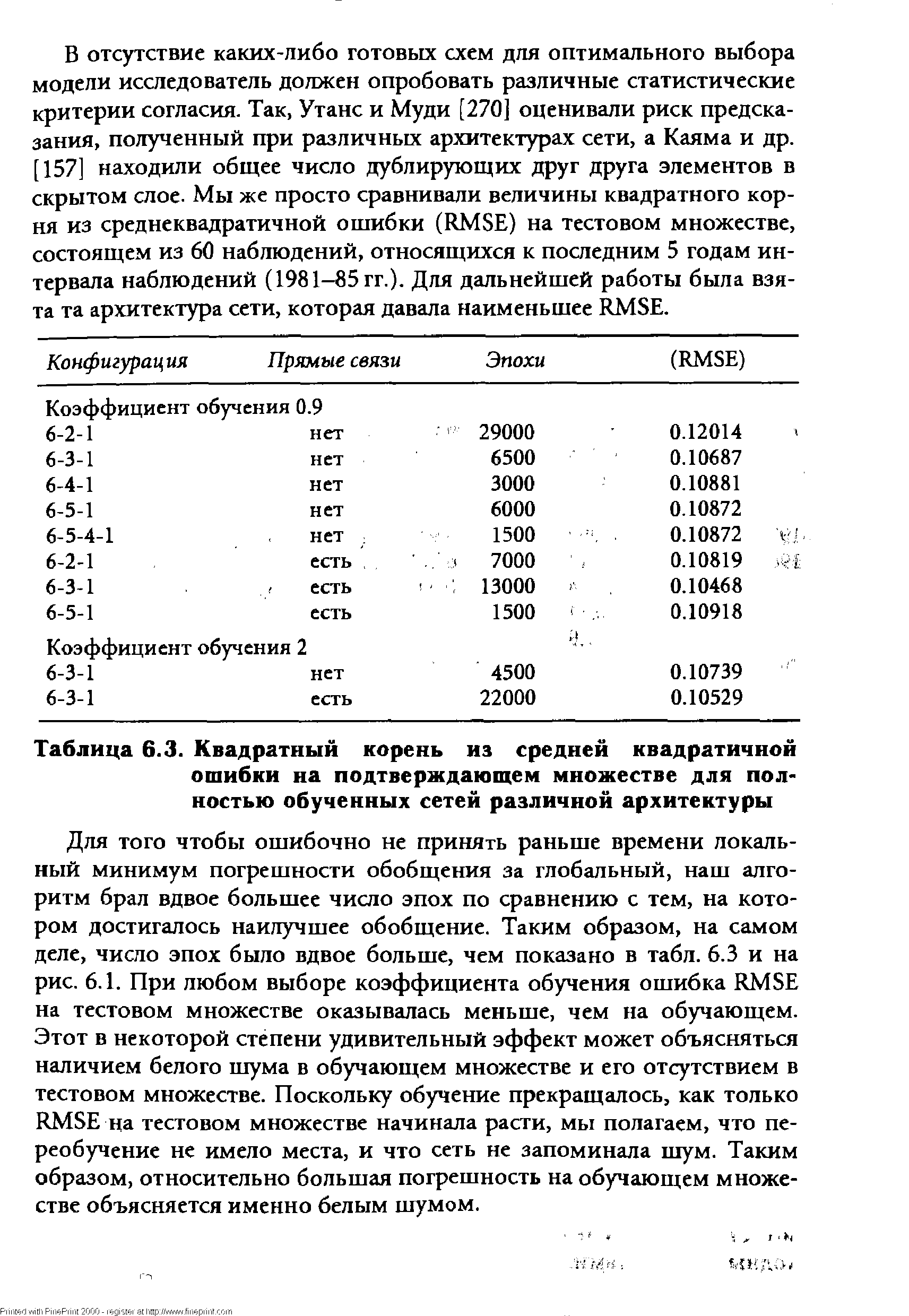 |
Б табл. 10.4 представлены результаты, которые показала обученная сеть на новых данных при различных значениях отсекающего порога. Транзакционные издержки, по-прежнему, в расчет не брались. Интересно, что с повышением порога (т.е. при уменьшении количества сделок) возрастали доли правильных сигналов и на покупку, и на продажу. По-видимому, те неэффективности (т.е. малые отклонения от 0.5-линии на рис. 10.3), которые имели место в периоде обучения (1970-е годы), подтвердились в проверочном периоде (1980-е годы). [c.223]
Привлекательной чертой нейрокомпьютинга является единый принцип обучения нейросетей -минимизация эмпирической ошибки. Функция ошибки, оценивающая данную конфигурацию сети, задается извне - в зависимости от того, какую цель преследует обучение. Но далее сеть начинает постепенно модифицировать свою конфигурацию - состояние всех своих синаптических весов - таким образом, чтобы минимизировать эту ошибку. В итоге, в процессе обучения сеть все лучше справляется с возложенной на нее задачей. [c.44]
В дальнейшем нам встретится множество конкретных методов обучения сетей с разными конфигурациями межнейронных связей. Чтобы не потерять за деревьями леса полезно заранее ознакомиться с базовыми нейро-архитектурами. В следующем разделе мы приведем такого рода классификацию, основанную на способах кодирования информации в сетях (обучения) и декодирования (обработки) информации нейросетями. [c.45]
Такой режим обучения сети называют обучением без учителя. В этом случае сети предлагается самой найти скрытые закономерности в массиве данных. Так, избыточность данных допускает сжатие информации, и сеть можно научить находить наиболее компактное представление таких данных, т.е. произвести оптимальное кодировние данного вида входной информации. [c.46]
Прежде всего, для любого из перечисленных методов необходимо определить критерий оптимальной сложности сети - эмпирический метод оценки ошибки обобщения. Поскольку ошибка обобщения определена для данных, которые не входят в обучающее множество, очевидным решением проблемы служит разделение всех имеющихся в нашем распоряжении данных на два множества обучающее - на котором подбираются конкретные значения весов. и валидационного - на котором оценивается предсказательные способности сети и выбирается оптимальная сложность модели. На самом деле, должно быть еще и третье - тестовое множество, которое вообще не влияет на обучение и используется лишь для оценки предсказательных возможностей уже обученной сети. [c.66]
Вначале все города оказывают приблизительно одинаковое влияние на каждую точку маршрута. В последующем, большие расстояния становятся менее влиятельными и каждый город становится более специфичным для ближайших к нему точек кольца. Такое постепенное увеличение специфичности, которое, конечно, напоминает уже знакомый нам метод обучения сети Кохонена, контролируется значением некоторого эффективного радиуса R. Если обозначить через X,. вектор, определяющий положение / -го города на плоскости, a Yy - [c.115]
Предсказания получены при обучении сети на 30 последовательных экспоненциальных скользящих средних (ЕМАч. .. ЕМАЗП) ряда приращений индекса. Предсказывался знак приращения на следующем шаге. [c.161]
Способность работать с неточными данными является одним из главных достоинств нейронных сетей. Но она же парадоксальным образом является и их недостатком. Действительно, если данные не точны, то сеть в силу своей гибкости и адаптируемости будет подстраиваться к ним, ухудшая свои свойства обобщения. Эта ситуация особенно важна при работе с финансовыми данными. В последнем случае существует множество источников погрешности. Это и ошибки при вводе числовых значений или неправильная оценка времени действия ценных бумаг (например, они уже не продаются). Кроме того, если даже данные и введены правильно, они могут быть слабыми индикаторами основополагающих экономических процессов, таких как промышленное производство или занятость. Наконец, возможно, что многие важные параметры не учитываются при обучении сети, что эффективно может рассматриваться как введение дополнительного шума. Данные, далеко выпадающие из общей тенденции, забирают ресурсы нейронной сети. Некоторые из нейронов скрытого слоя могут настраиваться на них. При этом ресурсов для описания регулярных слабо зашумленных областей может и не хватить. Множество попыток применения нейронных сетей к решению финансовых задач выявило важное обстоятельство контроль гибкости нейросетевой модели является центральной проблемой. Изложим кратко существо процедуры обучения сети, объединенной с исправлением данных. Для простоты рассмотрим сеть с одним входом и одним выходом. В этом случае минимизируемой величиной является сумма двух слагаемых (Weigend Zimmermann, 1996) [c.177]
В более общей постановке речь идет о прогнозировании финансового "здоровья" корпорации на основании ее финансовой отчетности. Нетривиальным моментом здесь является количественное определение финансового благополучия. Можно, как и в случае с облигациями, воспользоваться для обучения сети рейтингами, например, упомянутого выше агентства Value Line для воспроизведения этой, в общем-то субъективной оценки компании. Можно попытаться использовать в качестве индикатора благополучия более объективный критерий - рыночный курс акций в ближайшем или более отдаленном будущем (Бэстенс и др., 1997). Однако, рыночный курс может быть подвержен сильным флуктуациям чисто спекулятивного характера. Наконец, можно воспользоваться указаниями самого сурового учителя, исследуя крайнюю форму проявления финансового "недомогания" - банкротство. Анализ банкротств, таким образом, может служить источником объективных оценок устойчивости финансового положения фирм. [c.187]
Синаптические веса нейрона в сети Кохонена являются его координатами в исходном многомерном пространстве. Обучение сети т.е. нахождение положения узлов карты в многомерном пространстве происходит в режиме "победитель забирает все". Данные по очереди подаются на входы всех нейронов и для каждого входа определяется ближайший к нему нейрон. Обучение состоит в подгонке весов нейрона-победителя и его ближайших соседей минимизурующих отклонение данных от нейронов-победителей. Постепенно сеть находит равновесное положение, оптимально аппроксимирующее данные (см. Рисунок 6). [c.192]
Отметим что в отличие от анализа банкротств, описанного в первой части главы здесь информация о банкротствах не участвовала в обучении сети. Она изображена на уже готовой карте являсь лишь индикатором области параметров с повышенным риском банкротства. Эта особенность описываемой методики позволяет выявить область риска по относительно небольшому числу примеров (как в нашем случае). [c.194]
Та же самая задача может быть решена с использованием однослойной сети с единственным входным и единственным линейным выходным нейроном. Вес связи а и порог Ъ могут быть получены путем минимизации той же величины невязки (которая в данном случае будет называться среднеквадратичной ошибкой) в ходе обучения сети, например методом ba kpropagation. Свойство нейронной сети к обобщению будет при этом использоваться для предсказания выходной величины по значению входа. [c.200]
В отличие от нейросетевого подхода в котором основное время забирает обучение сетей при статистическом подходе это время тратится на тщательный анализ задачи. При этом опыт статистиков используется для выбора модели на основе анализа данных и информации, специфичной для данной области. Использование нейронных сетей - этих универсальных аппроксиматоров - обычно проводится без использования априорных знаний, хотя в ряде случаев оно весьма полезно. Например для рассматриваемой линейной модели использование именно среднеквадратичной ошибки ведет к получению оптимальной оценки ее параметров, когда величина шума имеет нормальное распределение с одинаковой дисперсией для всех обучающих пар. В то же время если известно, что эти дисперсии различны, то использование взвешенной функции ошибки [c.201]
Введенную Кохоненом [167] самоорганизующуюся карту признаков можно рассматривать как вариант нейронной сети. Сеть такого типа рассчитана на самостоятельное обучение во время обучения сообщать ей правильные ответы необязательно. В процессе обучения на вход сети подаются различные образцы. Сеть улавливает особенности их структуры и разделяет образцы па кластеры, а уже обученная сеть относит каждый вновь поступающий пример к одному из кластеров, руководствуясь некоторым критерием близости . [c.38]
Правильный выбор размера сети имеет важное значение. Хорошую, и притом очень маленькую, модель построить просто невозможно, а слишком большая будет чересчур сильно приспосабливаться к обучающим данным и плохо аппроксимировать настоящую задачу. Обычно начинают с сети небольшого размера и постепенно увеличивают ее, пока не будет достигнута нужная точность. При этом обучение сетей на каждом шаге проводится независимо. При другом подходе применяется алгоритм самонаращивания , когда по мере возникновения необходимости в сеть добавляются новые элементы, после чего заново происходит обучение (Stepnet, см. [164]). Упомянем также метод каскадной корреляции (см. [106]). Совершенно другая идея лежит в основе деструктивного подхода вначале берется сеть завышенного объема и из нее удаляются связи и узлы, существенно не влияющие на решение (см., например, [174]). При этом предполагается, что известна верхняя граница для размера [c.49]
Хотя на нейронные сети часто смотрят как на черный ящик , есть некоторые возможности выяснить влияние каждого фактора на решение, принимаемое в задаче классификации. На данное время формального метода, позволяющего извлекать из обученной сети информацию о задаче или о правилах классификации, не существует. Как правило, анализ сетей проводится эвристически (см. [127]). В рамках этой книги мы не имеем возможности рассмотреть все описанные в литературе методы выяснения стратегии классификации, которую осуществляет сеть. С некоторыми из таких методов мы встретимся позже (в частности, в гл. 4) при рассмотрении процедур моделирования. [c.50]
Этот пример является хорошей проверкой способности нейронной сети выявлять исходную структуру. Здесь мы опять использовали полносвязную 1-2-1 сеть без непосредственных связей входа с выходом, которая обучалась с помощью входных значений р(Ч и целевых значений р(. Для обработки сетью многократно подавались наборы из 100 пар значений цен. Как и в первом эксперименте, коэффициент обучения был взят равным 0.9. Во время обучения сети по окончании очередной эпохи (т.е. каждые 100 циклов) вычислялась среднеквадратичная ошибка (MSE). С самого начала этот показатель плавно уменьшался с каждой новой эпохой. Мы продолжали обучение до тех пор, пока MSE не установилась на своем минимальном [c.82]
Близкое прилегание к прямой, идущей под углом 45°, — очень хороший результат. Для крайних низких и высоких значений сохраняется расхождение, но за счет более длительного обучения и более тщательного выбора архитектуры и параметров сети можно добиться более точной аппроксимации сигмоидальной формы незашум-ленного процесса (обратите внимание, что крайних положительных значений больше). Веса обученной сети показаны на рис. 3.14. [c.89]
Этот же ряд мы проанализировали с помощью многослойной сети (MBPN). Зная вид модели, следовало бы взять сеть с двумя входами, но чтобы сохранить аналогию с четырьмя предыдущими значениями в методе Бокса-Дженкинса, мы выбрали архитектуру 4-2-1. Процесс обучения сети сходился не так хорошо, как в предыдущих двумерных примерах. При этом сходимость улучшалась, когда выбирались маленькие начальные значения весов (случайным образом на отрезке [-0.1,0.1]) и коэффициента обучения (0.1). Обучение прекращалось после 4000 эпох. В этот момент RMSE на пробном отрезке ряда (том же самом, что и в методе AR(4)) был равен 0.0649 и продолжал уменьшаться. Различие в точности прогноза сетью и линейной моделью оказалось здесь примерно таким же, как и в предыдущих экспериментах. Это хорошо видно на рис. 3.17, где результаты прогноза по обеим моделям сравниваются с точными значениями. [c.90]
При работе с набором данных о сделках, совершаемых в течение торгового дня, который был предоставлен Европейской биржей опционов (ЕОЕ), адаптивно обучаемая сеть WINNET показала лучшие результаты, чем статически обученная сеть и регрессия, по трем выбранным критериям. Простейшая основанная на этом прогнозе торговая стратегия принесла бы доход приблизительно в 11% годовых (без учета транзакционных издержек). [c.132]
Предполагая, что адаптивно обученная сеть может дать лучшие результаты, мы применили метод обучения при помощи движущегося окна. Для удобства сеть ALLNET повторно обучалась 100 раз, что дало в результате 404 прогноза (вместо 435). На выходе эта сеть (WINNET) уже не давала понижающего тренда, и это подтвердило наши представления о том, что метод адаптивного обучения имеет преимущество перед статическим обучением, использованным в ALLNET. [c.133]
Среди всех конфигураций наилучшей (имеющей наименьшее RMSE на подтверждающем множестве) оказалась 6-3-1 сеть с прямыми связями и коэффициентом обучения 0.9. Желая получить решение за кратчайшее время (в пределах 13 тыс. эпох), мы увеличили коэффициент обучения в два раза (до 2). Шаги в направлении градиента теперь стали очень большими, и мы перескакивали через решение. Поэтому даже оптимально обученной сети понадобилось гораздо больше, чем 13 тыс. эпох (а именно, 22 тыс.). На рис. 6.1 видно, как RMSE быстро убывает в первые 500 эпох, а после 12 тыс. эпох начинает осциллировать. [c.142]
Ее значение всегда лежит в интервале от 0 до 1, поскольку от того, что сеть при обучении улавливает содержащиеся в данных нелинейности, погрешность может только уменьшиться. Значения этого отношения для обучающего и проверочного множеств оказались равны, соответственно, 0.94 и 0.92, и это говорит о том, что либо сеть плохо использует свои нелинейные возможности, либо нелинейно-стей в данных просто нет. Мы подозреваем второе, потому что база данных строилась с помощью линейных моделей, для того чтобы выделить взаимно не коррелирующие экономические факторы. Большим значением данного отношения объясняется то обстоятельство, что обученная сеть лишь незначительно превосходит OLS-per-рессию по критерию RMSE. Однако остается фактом то, что нейронные сети превосходят OLS-регрессию даже при работе с такими данными, в которых нелинейные связи между входами и целевой переменной выражены слабо. [c.144]
Для обработки данных использовалась MBPN-сеть с логистическими функциями активации. Предполагалось, что после обучения сеть будет в состоянии правильно классифицировать новые (незнакомые ей) компании. В качестве исходной точки для сравнений была взята обычная линейная MDA-модель. Однако для метода MDA требуется, чтобы переменные были числовыми, — с буквенными или порядковыми переменными он работать не может. Проблема сведения всех показателей к числовым была решена при помощи нелинейного анализа главных компонент. [c.176]
В основу нейронной сети были положены семь входных переменных, базирующихся на показателях, входящих в Дзета-модель Альтмана. Поскольку банкротство — событие весьма редкое, а из компьютерной базы данных была исключена информация по обанкротившимся компаниям, мы не делали попыток обучить сеть на результат банкротство/выживание . Вместо этого в качестве целевой переменной при обучении сети было взято состояние курса акций компании относительно общего индекса курсов акций. При этом мы исходили из того, что при ухудшении состояния дел компании ее акции падают в цене. Таким образом, выходной сигнал сети— не двоичный (0,1), а представляет собой переменную с непрерывно меняющимися значениями. Одновременно использовалась еще одна переменная, которая разделяла выход на банкротов и небанкротов таким образом, чтобы достигалась наилучшая относительная точность прогноза и относительная цена ошибок. [c.207]
Для обучения сети были взяты данные по машиностроительным компаниям, акции которых котируются на фондовом рынке Великобритании. Обучающее множество состояло из данных по 20 компаниям за период времени с 1978 по 1986 гг. — всего 160 наблюдений. Модель представляла собой трехслойную сеть с семью входными элементами, соответствующими финансовым переменным. В скрытом слое было три элемента, и был также один выходной элемент. [c.207]
К сожалению, успех в применении технического анализа полностью зависит от качества метода оптимизации, о которой говорилось выше. Взяв длину промежутка для скользящего среднего равной, например, 125 дням, мы тем самым неизбежно ограничиваем свой выбор среди различных характеристик временных рядов для данной базы данных. Следует понимать, что такие действия, не сопровождающиеся достаточно хорошим подтверждением, могут привести к переобучению и потере способности к обобщению. Более того, многие инвесторы считают, что ключом к успеху в инвестиционном деле является интуиция аналитика, а не применение какой-либо процедуры отбора или формулы. В связи с этим Холи и др. [136] утверждают, что хотя успехи нейронных сетей в распознавании образов и делают возможным их использование в техническом анализе, все же наиболее выигрышные приемы будут, скорее всего, разработаны самими чартистами. Высказываются также предостережения против чрезмерной предварительной обработки входных данных, и поэтому мы воздержались от сверхоптимизации данных. Для того чтобы сохранить статистическую представительность данных, мы выбрали для обучения сети недельный промежуток времени. Для 5-20-1 сети это дает примерно 10 наблюдений на один весовой коэффициент. [c.213]