| Таблица 9.2 Классификация предприятий методом дискриминантного анализа | 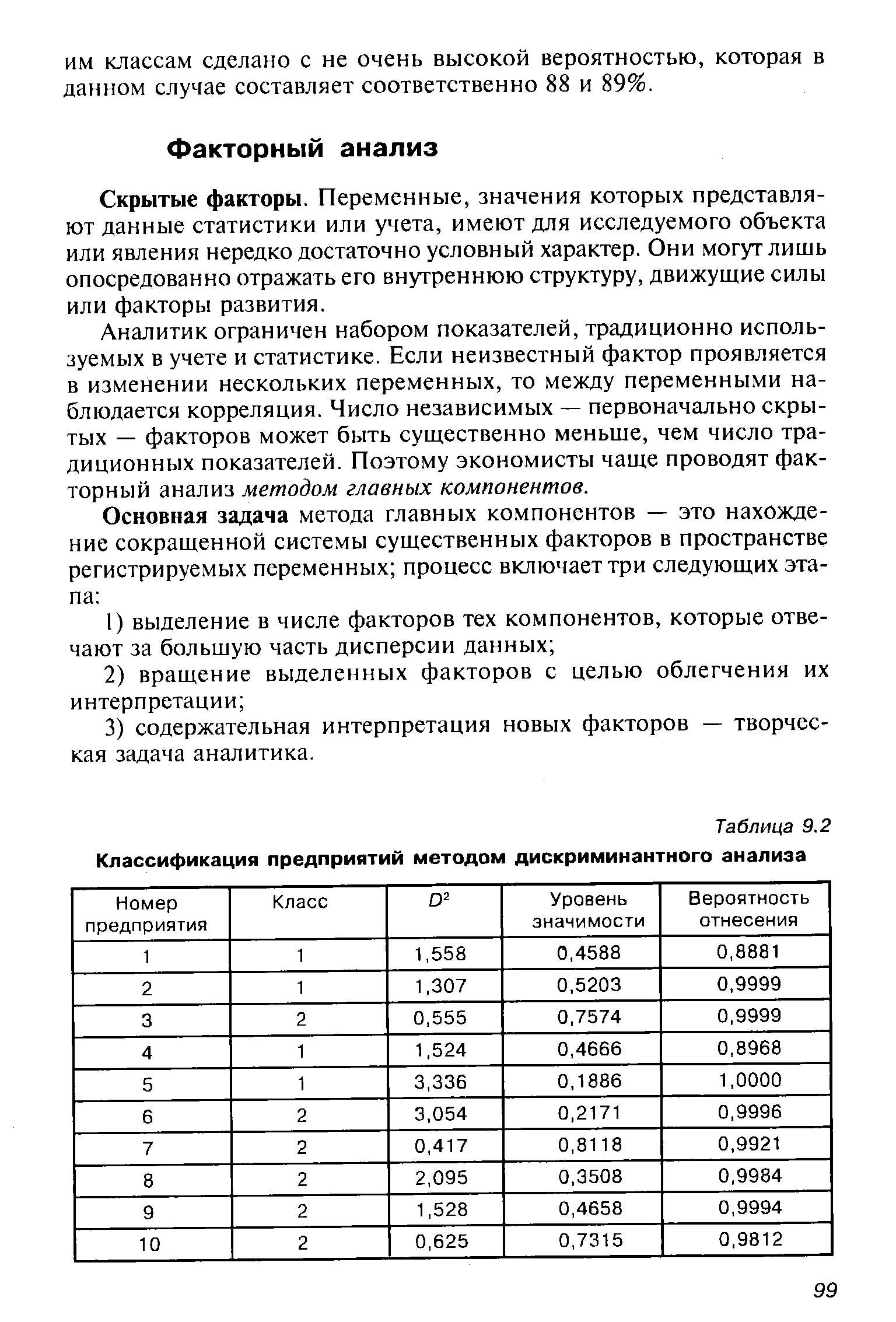 |
Метод кластерного анализа, позволяющий строить классификацию нескольких объектов посредством объединения их в группы, или кластеры, на основе критерия минимума расстояния в пространстве определенных показателей, описывающих объекты, а также классификацию объектов на заданное число групп — кластеров. Вероятностное обоснование результатов кластеризации можно получить методом дискриминантного анализа. [c.17]
Для моделирования закономерностей формирования качественного результата по количественным факторным показателям разработан метод дискриминантного анализа [8, с. 65—80, 101—158]. [c.109]
Надежность действующей в Бундесбанке системы рефинансирования основывается на четко отработанной методологии проверки платежеспособности и финансового состояния предприятий-заемщиков. При этом процедура проверки залога ужесточена в соответствии с требованиями Европейского центрального банка, который стандартизировал аналитические подходы. Полученная и обработанная информация оценивается с использованием метода дискриминантного анализа и экспертной системы в разрезе отдельных отраслей, а также с учетом разделения предприятий по объемам оборота (крупные, средние, малые). [c.16]
Метод дискриминантного анализа, когда переменная имеет две категории. [c.687]
Метод дискриминантного анализа, когда у зависимой переменной имеется три или больше категорий. [c.687]
Метод дискриминантного анализа, в котором дискриминантную функцию вычисляют при введении всех предикторов. [c.693]
Реализация статистического метода предполагает существование множества объектов, заданных некоторым набором признаков. Статистические характеристики признаков считаются известными полностью или частично. В основном используются дискриминантный анализ, выделение и выбор признаков, кластерный анализ. [c.203]
Дискриминантный анализ основывается на формировании функции, разделяющей различные классы объектов [121]. Используются квадратичные и линейные разделяющие функции, непараметрические методы, правила ближайшего соседа, оптимизация по критерию ошибки, иерархическое разделение, а также адаптивные разделяющие функции. [c.203]
В отличие от дискриминантного анализа, в кластерном анализе отсутствует однозначный количественный критерий оценки качества классификации типа ошибки. Кластерным называют анализ объектов, проводимый с целью выделения структур, классов, множеств подобных объектов. Существует большое разнообразие методов кластеризации. [c.204]
Дискриминантный (классифицирующий) анализ. Метод статистического анализа для определения признаков различия двух или более категорий объектов. [c.186]
Априорную плотность вероятности можно оценить различными способами. В параметрических методах предполагается, что плотность вероятности (PDF) является функцией определенного вида с неизвестными параметрами. Например, можно попробовать приблизить PDF при помощи гауссовой функции. Для того чтобы произвести классификацию, нужно предварительно получить оценочные значения для вектора среднего и матрицы ковариаций по каждому из классов данных и затем использовать их в решающем правиле. В результате получится полиномиальное решающее правило, содержащее только квадраты и попарные произведения переменных. Вся описанная процедура называется квадратичным дискриминантным анализом (QDA). В предположении, что матрицы ковариаций у всех классов одинаковы, QDA сводится к линейному дискриминантному анализу (LDA). [c.47]
На вход нейронного классификатора, показавшего наилучшую способность к обобщению (таким оказалась 3-1-1 сеть), была подана часть образцов. Результаты классификации (70-процентное попадание) выглядят обнадеживающе на фоне традиционных методов — линейного множественного дискриминантного анализа (MDA) и метода ближайшего соседа (1-NN). Однако способность сети к прогнозированию (56.7% правильных ответов) оказалась ниже ожидаемой. Можно предположить, что целевая переменная была не вполне правильно специфицирована для сомнительных компаний (пограничных случаев), и истинную картину можно будет установить, сравнивая результаты, полученные сетью, с реальными показателями в будущем. [c.194]
Традиционный подход к прогнозированию банкротств основан на множественном дискриминантном анализе (см. [7], [10], [12], [32], [33]). Методы такого типа используются в широко распространенных системах определения рейтинга кредитоспособности, где ищется гиперплоскость, наилучшим образом разделяющая хороших и плохих кандидатов. Хотя к настоящему времени разработано множество дискриминантных моделей, используется (в частности, в управлении кредитами) лишь небольшое число из них. В ряде случаев банки приходят к выводу, что методы MDA не дают ожидаемого улучшения точности по сравнению с традиционными методами. [c.200]
Дискриминантный (классифицирующий) анализ. Метод статистического анализа для определения признаков различия двух или более категорий объектов. Пример. Компания, владеющая сетью магазинов розничной торговли, может определить признаки, отличающие удачно расположенные торговые предприятия. [c.141]
Дискриминантные методы, применяемые для установки профиля сегментов, обычно используют множественный дискриминантный или регрессионный анализ. Такие статистические методы часто усиливаются графическими пакетами, которые показывают профиль сегментов. [c.275]
Сущность дискриминантного анализа близка к сущности регрессионного. Целью применения данного метода является аппроксимация распределения наблюдаемых объектов по значениям изучаемого качественного показателя. Для этого строится регрессионная функция по количественным факторным показателям таким образом, чтобы можно было найти определенное критическое значение (дискриминант) данной функции, которое отмечает границу распределения по качественному показателю. [c.109]
В маркетинговой литературе эту совокупность часто называют статистическим банком или банком моделей. Среди наиболее популярных методов математической статистики, входящих в этот банк, следует назвать регрессионный анализ, вариационный анализ, факторный анализ, дискриминантный анализ, кластерный анализ, многомерное шкалирование. [c.50]
Классификационные алгоритмы. К данным опроса для получения сегментов рынка могут быть применены, в частности, дискриминант-ный анализ и множественная регрессия. Дискриминантный анализ на практике используется для определения признаков разницы двух и более категорий объектов. Метод регрессионного анализа применяется для изучения зависимости результативного показателя от нескольких независимых переменных. Наиболее широко распространены методы множественной регрессии. [c.82]
Для того чтобы определить потребности покупателей, необходимо провести маркетинговые исследования. На первом этапе они обычно включают неформальный опрос потенциальных покупателей и фокус-групп с целью выяснения ценных для респондентов благ и различий в их ожиданиях. Например) кто из них отдает приоритетное значение невысоким ценам, а для кого главное — имидж и качество товара На втором этапе составляется формальная анкета, заполняемая большой группой респондентов для количественной оценки различий в потребностях. Для выбора наиболее значимых переменных сегментирования рынка используются различные методы статистики, например, дискриминантный [c.99]
Установление профилей сегментов. Для этого используются многомерные статистические методы. В основном это дискриминантный анализ, множественная регрессия, многомерный факторный анализ. [c.88]
В дискриминантном анализе формирование разделяющих функций основывается на одном из статистических или эвристических методов. Статистические методы нацелены на минимизацию ошибки классификации, представляющей собой вероятность неправильной классификации поступившего на распознавание k-мерного объекта X. К таким методам относят [1] [c.268]
Многомерный статистический анализ — раздел математической статистики, объединяющий методы изучения статистических данных, которые являются значениями многомерных качественных или количественных признаков. Включает дискриминантный анализ, кластер-анализ и другие математико-статистические методы, как правило, не опирающиеся на предпосылку о вероятном [c.216]
Классический кредитный анализ традиционно применяется банками для оценки кредитоспособности заемщика на основе таких показателей, как деловая репутация, размер капитала, уровень финансового рычага , колебания рентабельности, предлагаемое обеспечение и т. д. Однако проведение такого рода анализа требует больших затрат времени и средств на оплату труда квалифицированных экспертов. Поэтому банки стали склоняться к формализации процесса принятия решений по кредитованию, а с появлением современных математических методов неплатежеспособность стала предметом серьезных статистических исследований. Большинство исследований в этой сфере были построены на использовании дискриминантного анализа. Одна из наиболее успешных работ в этой области принадлежит Альтману, который опубликовал в 1968 г. описание своей Z-модели , получившей широкую известность и применение на практике. [c.342]
Дискриминантный анализ. Предполагается, что имеется совокупность объектов, разбитая на несколько групп (т.е. для каждого объекта мы можем сказать, к какой группе он относится). Для каждого из этих объектов имеются измерения нескольких количественных характеристик. Методы дискриминантного анализа позволяют отне- [c.285]
Подход Альтмана, называемый также методом дискриминантного анализа, был впоследствии применен самим Альтманом и его последователями в ряде стран (Англия, Франция, Бразилия и т.п.). Так, например Тоффлер и Тисшоу [3.5], для случая Великобритании получили следующую зависимость [c.45]
Следующий шаг был предпринят Эдвардом Альтманом [104 - 106] в 1968 году, который в многомерном пространстве ряда частных коэффициентов сориентировал гиперплоскость таким образом, что фазовые точки в гиперпространстве, отвечающие эффективно работающим предприятиям, оказались по одну сторону гиперплоскости, а фазовые точки предприятий, движущихся к банкротству - по другую. Соответствующая Z-оценка, полученная как свертка отдельных показателей с весами, вычисленными с помощью метода дискриминантного анализа, является комплексной оценкой финансового состояния предприятия. Альтман пронормировал свою Z-оценку, введя состояния нормального финансового положения с минимальным риском банкротства, промежуточное состояние с растущим риском банкротства и состояние, когда риск банкротства угрожающе высок. [c.23]
Одно из интересных приложений метода МДА - оценка платежеспособности фирмы. Французы Ж.Конан и М.Голдер1 на основе изучения 95 малых и средних предприятий Франции разработали модель, позволяющую оценить вероятность задержки платежей фирмой в зависимости от значения следующего дискриминантного показателя [c.387]
Пионерская работа Альтмана в этом направлении датируется 1968 годом (Altman, 1968). Используя метод линейного дискриминантного анализа он выявил пять наиболее значимых финансовых индикаторов, влияющих на предсказание банкротств [c.187]
Поскольку в настоящее время нейронные сети с успехом используются для анализа данных, уместно сопоставить их со старыми хорошо разработанными статистическими методами. В литературе по статистике иногда можно встретить утверждение, что наиболее часто применяемые нейросетевые подходы являются ни чем иным, как неэффективными регрессионными и дискриминантными моделями. Мы уже отмечали прежде, что многослойные нейронные сети действительно могут решать задачи типа регрессии и классификации. Однако, во-первых, обработка данных нейронными сетями носит значительно более многообразный характер - вспомним, например, активную классификацию сетями Хопфилда или карты признаков Кохонена, не имеющие статистических аналогов. Во-вторых, многие исследования, касающиеся применения нейросетей в финансах и бизнесе, выявили их преимущества перед ранее разработанными статистическими методами. Рассмотрим подробнее результаты сравнения методов нейросетей и математической статистики. [c.198]
Логистическая регрессия является методом бинарной классификации, широко применяемом при принятии решений в финансовой сфере. Она позволяет оценивать вероятность реализации (или нереализации) некоторого события в зависимости от значений некоторых независимых переменных - предикторов xb...,xN. В модели логистической регресии такая вероятность имеет аналитическую форму Pr(x) =(l+exp(-z ))", где z = ao+ aiXi+...+ aNxN. Нейросетевым аналогом ее очевидно является однослойный персептрон с нелинейным выходным нейроном. В финансовых приложениях логистическую регрессию по ряду причин предпочитают многопараметрической линейной регрессии и дискриминантному анализу. В частности, она автоматически обеспечивает принадлежность вероятности интервалу [0,1], накладывает меньше ограничений на распределение значений предикторов. Последнее очень существенно, поскольку распределение значений финансовых показателей, имеющих форму отношений, обычно не [c.202]
У Очень важной является проблема диагностирования инфаркта миокарда в приемном покое. Опытные врачи правильно определяют это заболевание в 88% случаев и в 29% случаев дают ложную тревогу. Разнообразные статистические методы, включая дискриминантный анализ, логистическую регрессию, рекурсивный анализ распределений и пр. смогли лишь незначительно снизить число ложных тревог (до 26%). А вот Вильям Бакст, работающий на медицинском факультете университета в Сан-Диего, использовал для диагностики многослойный персептрон и повысил число правильно диагностированных инфарктов до 92%. Но более впечатляющим [c.203]
При использовании количественных моделей исходят из того, что шансы компании на выживание можно оценить, отслеживая, как меняются со временем соотношения между различными финансовыми показателями. Обсудим вкратце два наиболее известных метода такого рода — множественный линейный дискриминантный анализ (MDA = Multiple Dis riminant Analysis) и регрессию. [c.168]
Включает дискриминантный анализ, кластер-анализ и другие матема-тико-статистические методы, как правило, не опирающиеся на предпосылку о вероятностном характере исследуемых зависимостей (см. Прикладная статистика). В частности, дискриминантный анализ предназначен для решения задач, связанных с разделением совокупностей наблюдений (элементарных данных). Если у исследователя имеется по одной выборке из каждой неизвестной ему генеральной совокупности (такую выборку называют "обучающей"), то с помощью методов дискри-минантного анализа удается приписать некоторый новый элемент (наблюдение х) к своей генеральной совокупности. [c.199]
Для оценки вероятности банкротства в зарубежной практике широко используются количественные методы, такие, KaKZ-модели, разработанные Альтманом в 1968 г. Модель Альтмана представляет дискриминантную линейную функцию с различным числом переменных. В зависимости от этого различают двух-, пяти- и семифак-торные модели. Параметры дискриминантной функции рассчитываются путем статистической выборки по обанкротившимся или избежавшим банкротства предприятиям. [c.64]
Анализ и обобщение данных осуществляются методами ручной, компьютерной (полукомпьютерной), когда используется карманный компьютер, и электронной (с использованием персонального или большого компьютера) обработки. Для обработки используются как описательные, так и аналитические методы. Среди аналитических методов в маркетинге часто применяются анализ трендов, методы нелинейной регрессии и коррекции, дискриминантный анализ, кластерный анализ, факторный анализ и др. Возможные направления применения отдельных аналитических методов показаны в табл. 2.13. [c.118]
Дискриминантный анализ представляет собой математически-статистический метод, с помощью которого объекты, имеющиеся в базе данных, могут быть разделены на заданное количество групп по заранее установленным критериям. При этом по полученному обобщающему показателю, представляющему собой экономически интерпретируемый коэффициент, каждое предприятие можно классифицировать с точки зрения его платежеспособности. В зависимости от значения полученного обобщающе- [c.16]
Модель Альтмана была построена при помощи множественного линейного дискриминантного анализа (multiple dis riminant anafysis — MDA) — статистического метода, который позволяет подобрать такие классифицирующие переменные, дисперсия которых между рассматриваемыми группами была бы максимальной, а внутри этих групп — минимальной. В данном случае классификация производилась только по двум группам компании, потерпевшие в последующем банкротство, и компании, сумевшие его избежать. Построение такой модели представляет собой пошаговый процесс, в ходе которого последовательно включаются или исключаются переменные на основе различных статистических критериев. [c.342]
Если есть только одна зависимая переменная, используются такие методы как дисперсионный и ковариационный анализ, регрессионный анализ, дискриминантный анализ и совместный анализ. Однако, если имеется больше одной зависимой переменной, следует воспользоваться многомерными методами анализа дисперсионным и ковариационным, методом канонической корреляции и множественным дис-криминантным анализом. При применении методов взаимозависимости (interdependent te hniques) переменные не подразделяются на зависимые и независимые напротив, исследуется весь набор взаимозависимых взаимосвязей. [c.541]
Смотреть страницы где упоминается термин Методы дискриминантные
: [c.69] [c.74] [c.2] [c.16] [c.169] [c.178] [c.71] [c.24] [c.357]Маркетинг (2002) -- [ c.381 ]